Issue Grouping
Learn about fingerprinting, Sentry's default error grouping algorithms, and other ways to customize how events are grouped into issues.
A fingerprint is a way to uniquely identify an event, and all events have one. Events with the same fingerprint are grouped together into an issue.
By default, Sentry will run one of our built-in grouping algorithms to generate an event fingerprint based on information available within the event. The available information and the grouping algorithms vary by event type. Sentry fingerprints error events based on information like stacktrace, exception, and message. Transaction events are fingerprinted by their spans.
Each time default error grouping behavior is modified, Sentry releases it as a new version. As a result, modifications to the default behavior do not affect the grouping of existing issues.
When you create a Sentry project, the most recent version of the error grouping algorithm is automatically selected. This ensures that grouping behavior is consistent within a project.
To upgrade an existing project to a new error grouping algorithm version, navigate to Settings > Projects > [project] > Issue Grouping > Upgrade Grouping. After upgrading to a new error grouping algorithm, you will very likely see new groups being created.
All versions consider the fingerprint first, the stack trace next, then the exception, and then finally the message.
To see how an isssue was grouped, go to its Issue Details page and scroll down to "Event Grouping Information". There, you'll see if it was grouped by a fingerprint, stack trace, exception, or message.
Some kinds of errors, like chunk load errors and hydration errors, often have various different error types, values, or transaction messages that may result in separate but similar issues. To better handle these cases, Sentry maintains a set of built-in fingerprinting rules to better group such errors.
Issues grouped by Sentry's built-in fingerprinting rules will list "Sentry Defined Fingerprint" in the "Event Grouping Information" at the bottom of the Issue Details page.

Built-in fingerprinting rules work the same as custom fingerprinting rules and are applied by default. If an user defined custom fingerprinting rule matches an event, the custom rule will always take precedence over the built-in ones.
When Sentry detects a stack trace in the event data (either directly or as part of an exception), the grouping is effectively based entirely on the stack trace.
The first and most crucial part is that Sentry only groups by stack trace frames that the SDK reports and associates with your application. Not all SDKs report this, but when that information is provided, it’s used for grouping. This means that if two stack traces differ only in parts of the stack that are unrelated to the application, those stack traces will still be grouped together.
Depending on the information available, the following data can be used for each stack trace frame:
- Module name
- Normalized filename (with revision hashes, and so forth, removed)
- Normalized context line (essentially a cleaned up version of the source code of the affected line, if provided)
This grouping usually works well, but two specific situations can throw it off:
- Minimized JavaScript source code will destroy the grouping in detrimental ways. To avoid this, ensure that Sentry can access your Source Maps.
- Modifying your stack trace by introducing a new level through decorators changes your stack trace, so the grouping will also change. To handle this, many SDKs support hiding irrelevant stack trace frames. For example, the Python SDK will skip all stack frames with a local variable called
__traceback_hide__set to True.
If the stack trace is not available, but exception information is, then the grouping will consider the type and value of the exception if both pieces of data are present on the event. This grouping is a lot less reliable because of changing error messages.
Grouping falls back to messages if the stack trace, type, and value are not available. When this happens, the grouping algorithm will try to use the message without any parameters. If that is not available, the grouping algorithm will use the full message attribute.
In addition to fingerprint-based grouping, Sentry uses AI to further improve issue grouping accuracy. This system helps identify semantically similar errors that might have different fingerprints due to minor code variations. The AI grouping system works alongside traditional fingerprinting - it only attempts to group new issues and will never split up issues that were grouped by fingerprint.
This system will not apply to any events that have fully custom fingerprints (either set via SDK or fingerprint rules). However, events with fingerprints containing {{ default }} will use AI grouping to calculate the {{ default }} portion of the fingerprint.
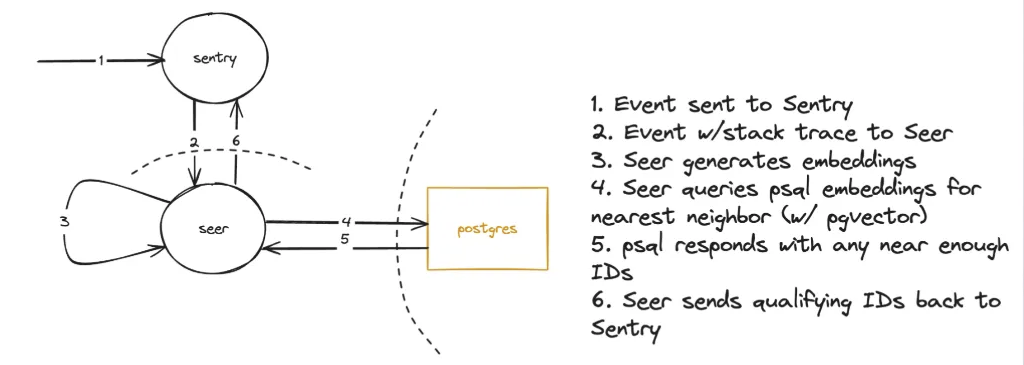
When Sentry's default fingerprinting algorithm generates a new hash, it automatically sends the error data to Seer, our AI/ML service. That error data includes the message and in-app stack frames (including those configured with stack trace rules), or all frames when no in-app frames are present.
Seer performs the following steps:
- It generates a vector representation of the error's stack trace using a transformer-based text embedding model
- It compares this embedding against existing error embeddings for that project in the database
- If a semantically similar error is found within the configured threshold, Sentry merges the new error into the existing issue
This algorithm is particularly effective at handling cases where:
- Similar errors occur in different parts of the codebase
- Code changes or deployments introduce slight variations in stack traces
- Different error types represent the same underlying problem
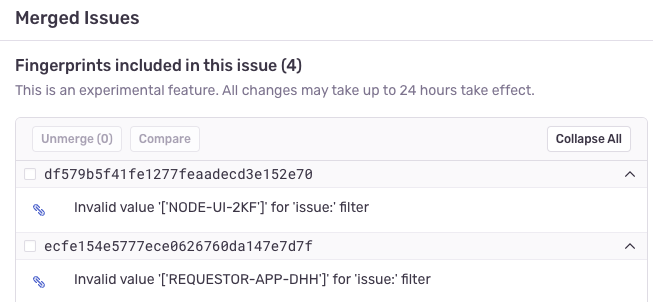
You can see issues that have been merged through this system in the “Merged Issues” section of the Issue Details UI. You can always unmerge any fingerprints that you would not like to see grouped, and our system will avoid grouping them in the future.
If the way that Sentry is grouping issues for your organization is already ideal, you don't need to make any changes. However, you may find that Sentry is either creating too many similar groups, or is grouping disparate events into groups that should be separate. If this is the case, for error issues, you can extend and change the default grouping behavior. Error grouping can be extended and changed completely according to your needs. Transaction grouping currently cannot be customized.
You can customize error grouping using a combination of the following options, listed from least to most complex:
- In your project, by Merging Issues
Merges together similar issues that have already been created. No settings or configuration changes are required for this.
- In your project, using Fingerprint Rules
Sets a new fingerprint for incoming events based on matchers. This doesn't affect already existing issues.
- In your project, using Stack Trace Rules
Sets rules for how incoming events should be treated based on matchers. This doesn't affect already existing issues.
- In your SDK, using SDK Fingerprinting
Sets a new fingerprint for incoming events based on matchers in the SDK. This doesn't affect already existing issues. Note that is not supported in WebAssembly.
Stack trace rules can work as a combination of both SDK and project settings. As a result, we maintain the documentation in one location.
You can see a fingerprint by opening an issue, clicking " View JSON", and finding the fingerprint property in that file. If the default grouping was used, you'll see "default" written there. If a different grouping was used, you'll see the actual fingerprint value itself.
Sentry groups transactions with performance problems into performance issues using the transaction's spans. We fingerprint by the span evidence related to the performance problem found in the event. This includes the spans directly involved in the problem, as well as spans that might have caused the problem or are closely related to it. This algorithm isn't currently customizable or extendable.
Our documentation is open source and available on GitHub. Your contributions are welcome, whether fixing a typo (drat!) or suggesting an update ("yeah, this would be better").